
INTRODUCCIÓN
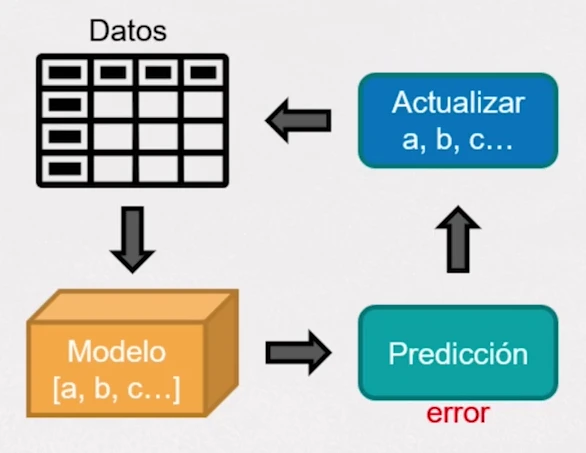
El uso correcto de técnicas de selección de algoritmos es vital en trabajos de investigación, así como en aplicaciones de negocio. Acertar en la predicción de datos futuros es uno de los principales desafíos a la hora de desarrollar nuevos modelos predictivos o algoritmos.
Cuando disponemos de resultados de dos o más modelos de machine learning (aplicados sobre mismos o distintos conjuntos de datos) y necesitamos compararlos formalmente para determinar cuál se comporta mejor ante un determinado problema, no sería formalmente válido escoger aquel que mejor resultado o métrica haya dado. Hay que demostrar que las diferencias son estadísticamente significativas, y no debidas al azar o ruido en los datos, de lo contrario no podemos asumir que los modelos en cuestión se comportan de forma distinta.
Introdución
Desde el punto de vista estadístico, se establece una hipótesis nula a refutar:
H0
">H0: los modelos presentan el mismo rendimiento, dicho de otra forma, las métricas escogidas para evaluar su desempeño son iguales.
Para dicho fin, tenemos a nuestra disposición un conjunto de técnicas o test estadísticos que podemos aplicar a los resultados de la calibración de nuestros modelos. En este sentido, podemos hablar de test estadísticos paramétricos y no paramétricos:
• Test paramétricos: asumen que los datos se distribuyen acorde a una determinada distribución estadística conocida (normal, Bernoulli, etc.). Además, son sensibles a outliers y suposiciones de independencia, normalidad y homocedasticidad. Por tanto, los datos deben cumplir ciertas condiciones para que los resultados de estos test sean fiables.
• Test no paramétricos: no asumen ninguna distribución en los datos. Los test paramétricos suelen preferirse sobre los no paramétricos ya que suelen caracterizarse por un mayor poder estadístico, esto es, son capaces con mayor probabilidad de detectar una diferencia estadísticamente significativa si esta existe.
En función del problema, podemos recurrir a diferentes técnicas de remuestreo (validación cruzada de k
">kk
pliegues, LOOCV, etc.) para calibrar nuestros modelos con datos de entrenamiento, así como diferentes métricas para determinar la eficiencia de los mismos.
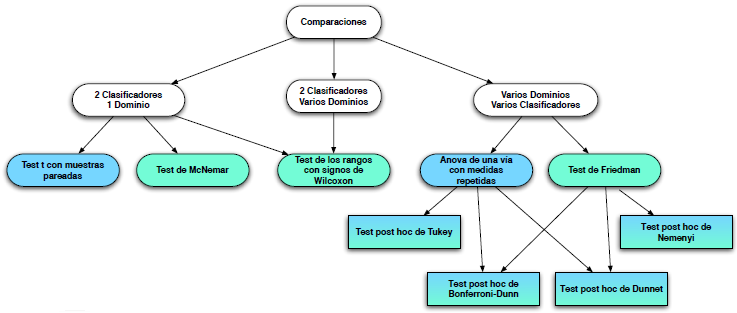
Un aspecto importante a tener en cuenta a la hora de determinar el tipo de test estadístico apropiado a aplicar es si contamos con medidas pareadas, es decir, métricas de los distintos modelos sobre el mismo conjunto de datos, o medidas sobre muestras independientes. En función de esto, podemos encontrarnos con distintos escenarios:
• Dos modelos en un mismo dominio o conjunto de datos.
• Varios modelos en un mismo dominio o conjunto de datos.
• Dos modelos en dominios o conjuntos de datos distintos.
• Varios modelos en dominios o conjuntos de datos distintos.
Los test aplicables para cada caso se recogen en el siguiente esquema:
Dos modelos en un solo dominio
Supongamos que contamos con un modelo clasificador A y un modelo clasificador B, y que para la calibración se ha aplicado una validación cruzada de k pliegues. Por cada pliegue, se utiliza un subconjunto de entrenamiento y validación distinto, a partir de los cuales obtenemos k medidas o métricas, que serán las que compararemos estadísticamente. Los test de este apartado se ejemplificarán en base a este ejemplo.
Test t de Student pareado
Permite determinar si la media de las diferencias entre dos muestras pareadas es significativa, es decir, diferente de 0.
HIPÓTESIS
H0: µA - µB = 0 (La diferencia entre las medias pareadas de ambos grupos es igual a 0).
H1: µA - µB ≠ 0 (La diferencia entre las medias pareadas de ambos grupos es distinta de 0).
CONDICIONES
- Mismas muestras para cada grupo.
- Aleatoriedad de la muestra: las muestras a partir de las cuales se calculan las medias deben haber sido seleccionadas de forma independiente, siendo estas representativas.
- Normalidad: Las métricas de ambos modelos deben seguir una distribución normal. Entre los test comúnmente aplicables para comprobar este requerimiento se encuentran: Kolmogorov-Smirnov (recomendado con n>50), Saphiro Wilk (recomendado con n<50). Si esta condición no se cumple, el test t de Student puede ser robusto con conjuntos de test con más de 30 muestras. En el caso de aplicar validación cruzada con k pliegues, necesitaríamos un conjunto con k x 30 muestras. Otra opción sería aplicar esta validación cruzada con repetición para obtener al menos 30 medidas por pliegue.
ESTADÍSTICO
Para el ejemplo comentado anteriormente, para cada observación i del conjunto de datos n, el test calculará las m diferencias (correspondientes al número de pliegues de validación cruzada) entre el modelo A y el modelo B:
La ecuación para calcular el estadístico t sería:
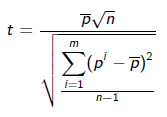
donde
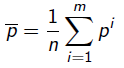
Este estadístico sigue una distribución ">t ">m−1, ">α/2 ">H0
Con este test podemos saber si la diferencia entre modelos es significativa, pero no nos aporta información sobre cuán importante es la diferencia, si es que existe. Para ello se calcula el estadístico d de Cohen, el cual es una medida del tamaño del efecto en base a la diferencia estandarizada de dos medias:
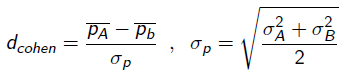
El valor de este estadístico corresponde con las desviaciones típicas de diferencia entre los dos grupos. Una escala aproximada para interpretar el tamaño del efecto según este estadístico sería:
dcohen = 0,2-0,3 (pequeño)
dcohen = 0,5 (mediano)
dcohen = 0,8 (grande)
Consideraciones:
Aunque este test es potente en base al uso de una validación cruzada con 10 pliegues, puede en este caso presentar un Error de Tipo I (detectar diferencias cuando no las hay) alto. Se recomienda en casos en los que el Error de Tipo II (fallar en detectar una diferencia real entre modelos) es más importante.
Test t de Student pareado y test de McNemar
Test de McNemar
El test de McNemar se presenta como alternativa no paramétrica al test ">tt

HIPÓTESIS
La hipótesis nula establece que ambos clasificadores tienen el mismo ratio de error:
">H0
:">n01
=">n10
">n01
+">n10
> 20.ESTADÍSTICO
El estadístico, que se ajusta a una distribución Chi-cuadrado ( ">χ2χ2
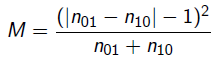
">α
, la hipótesis nula no se rechaza si, M≤x 2α,1